


Breaking the Bias: Addressing Imbalanced Data in Machine Learning
Enhancing the fairness of machine decisions

Imbalanced data in classification models occurs when the number of observations in each class is disproportionately distributed. This imbalance poses a significant challenge in machine learning, leading to models that often favor the majority class and underrepresent the minority class. Initially, simple metrics like accuracy were used to evaluate models, which masked the poor performance of the minority class. Over time, the field has recognized the importance of developing and applying specialized techniques to address these imbalances, leading to more sophisticated methods and metrics that offer a fairer evaluation of model performance.
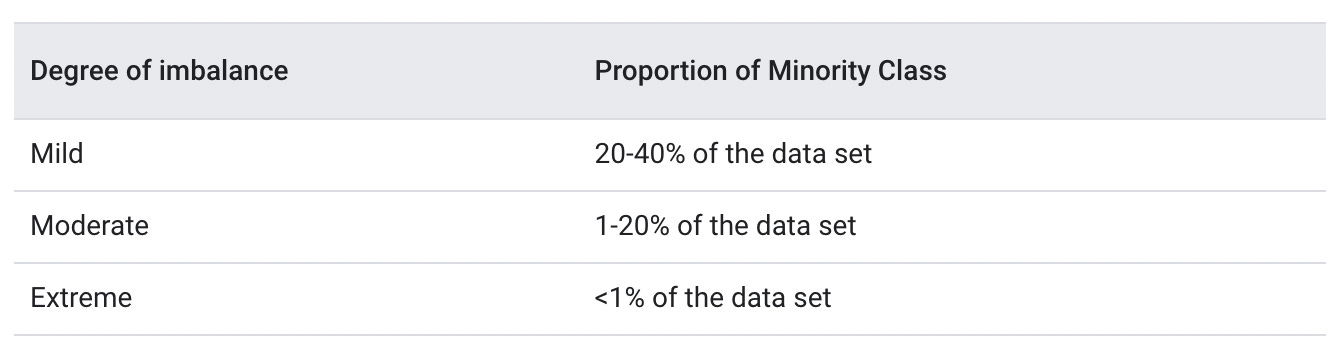
What counts as imbalanced? The answer could range from mild to extreme, as the table below shows, referring to the Google Cloud machine learning fundamental course. For example, in fraud detection, fraudulent transactions may represent only 1% of the data, significantly skewing model development, and evaluation.
The Impact of Imbalanced Data on Classification Models
Imbalanced datasets can lead models to develop a bias towards the majority class, neglecting the minority class which is often of greater interest. For instance, an anti-fraud model trained on imbalanced data may predict most users as not fraudulent because the majority of the training data is healthy users. This results in high overall accuracy but poor ability to detect the actual fraud cases. The model will predict poorly if any fraudulent transaction happens in the future.

Metrics for Evaluating Models on Imbalanced Data
Traditional metrics like accuracy are not suitable for imbalanced datasets as they can be misleading, as we discussed briefly previously. For instance, a model might show high accuracy in predicting non-fraudulent transactions simply because they make up the majority of the data. Alternative metrics such as the F1-score, which balances precision and recall, and AUC-ROC, which considers the rate of true positive and false positive rates, provide more insight into the model’s performance on imbalanced data.

Dealing with Imbalanced Dataset
There are 3 most common techniques to address imbalanced data problems. I will discuss three of them briefly in this article and will discuss them in more detail in another article.
Resampling Techniques
Algorithmic Adjustments
Advanced Synthetic Techniques
Resampling Techniques
Resampling techniques are one of the primary strategies for dealing with imbalanced datasets. Oversampling the minority class can help by increasing its representation in the training set while undersampling the majority class reduces its observations. However, these methods have limitations such as potential overfitting with oversampling and loss of valuable information with undersampling.

In Python, we can use common libraries like pandas for data manipulation and imblearn (imbalanced-learn) for dealing with imbalanced data. This provides straightforward tools to implement these techniques. Below is the simple code for oversampling to understand more on the oversampling implementation.
from sklearn.datasets import make_classification
from imblearn.over_sampling import RandomOverSampler
import pandas as pd
# Create a dummy dataset
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.01, 0.99], n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=10000, random_state=10)
# Convert to DataFrame for easier manipulation
df = pd.DataFrame(X)
df['target'] = y
# Display original class distribution
print("Original class distribution:")
print(df['target'].value_counts())
# Apply Random Over Sampling
ros = RandomOverSampler(random_state=42)
X_res, y_res = ros.fit_resample(X, y)
# Convert resampled data back to DataFrame
df_resampled = pd.DataFrame(X_res)
df_resampled['target'] = y_res
# Display new class distribution
print("New class distribution after oversampling:")
print(df_resampled['target'].value_counts())
Algorithmic Adjustments and Ensemble Techniques
Classic Random Forest is a powerful and widely used machine learning model, known for its robustness, simplicity, and ability to perform both classification and regression tasks. However, like many other machine learning models, Random Forest can perform poorly on imbalanced datasets where one class significantly outnumbers another.
This can be handled by modifying the algorithms to make them sensitive to class distribution or employing ensemble techniques that integrate multiple models to improve performance are effective strategies for imbalanced data. For example, Balanced Random Forests adjusts the classic Random Forest algorithm to better handle imbalances by balancing the data in each bootstrap sample.
In traditional Random Forest, each tree is trained on a bootstrap sample (a randomly selected subset with replacement) of the training data. This usually preserves the original class distribution, which can bias trees towards the majority class. In contrast, the Balanced Random Forest modifies this process by balancing the class distribution within each bootstrap sample. It either undersamples the majority class or oversamples the minority class (or both) to ensure that each tree is trained on a dataset where all classes are equally represented. This change helps each tree to develop a better understanding and sensitivity towards the minority class.
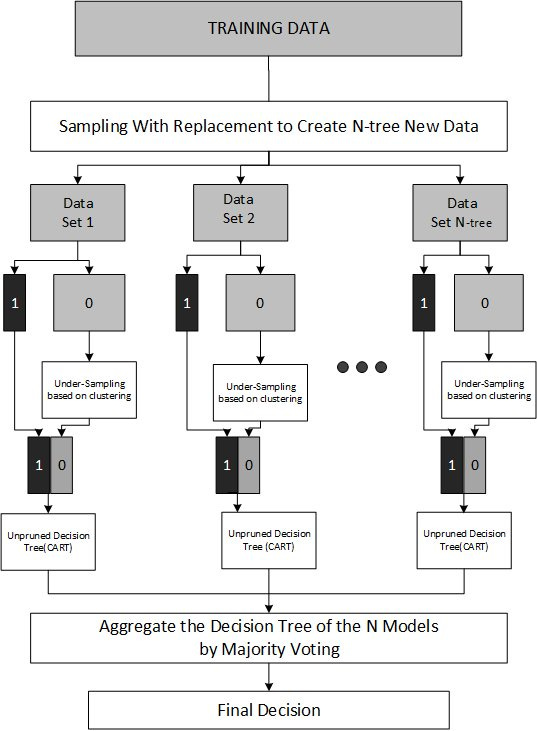
As this is a more advanced technique, for the Python code I will discuss this further in another article.
Advanced Synthetic Techniques
Techniques like SMOTE and ADASYN do not plainly replicate minority class instances but create synthetic samples based on the existing ones, potentially providing a richer dataset for training models. These techniques have been developed further to address specific challenges and improve performance across various conditions.
SMOTE works by creating synthetic samples from the minor class instead of creating copies by utilizing k-NN algorithm. This approach helps to overcome the overfitting problem, which arises when exact copies of minority class examples are added to the training set.
While ADASYN builds on the methodology of SMOTE by shifting the importance of the classification boundary to those examples that are difficult to learn. The main idea behind ADASYN is to use a weighted distribution for different minority class examples according to their learning difficulty. More synthetic data is generated for minority class examples that are harder to learn, as opposed to those that are easier.

Similar to the algorithmic adjustment technique, as this is a more advanced technique, I will discuss this further in another article.
Conclusion
Handling imbalanced data is crucial for building fair and accurate classification models. We have covered a range of methods from basic resampling to more advanced synthetic techniques, offering a set of tools for improving the performance of models, and ensuring that minority classes are adequately represented, to improve the machine decision fairness
Reference:
https://towardsdatascience.com/handling-imbalanced-datasets-in-machine-learning-7a0e84220f28
https://developers.google.com/machine-learning/data-prep/construct/sampling-splitting/imbalanced-data
https://medium.com/analytics-vidhya/undersampling-and-oversampling-an-old-and-a-new-approach-4f984a0e8392
https://www.researchgate.net/publication/341150801_Modified_balanced_random_forest_for_improving_imbalanced_data_prediction
https://towardsdatascience.com/smote-synthetic-data-augmentation-for-tabular-data-1ce28090debc